










Od czasu do czasu mam w zwyczaju przeglądać cały swój kod i w razie potrzeby robić jego refaktoryzację, tak też się stało tydzień temu kiedy stwierdziłem, że zamiast dopisywać nową funkcjonalność do projektu Silverlight, doprowadzę do porządku to co już stworzyłem.
Podczas przeglądania kodu, natrafiłem na taką o to extension method:
using System;
using System.Collections.Generic;
namespace SlPerfTest
{
public static class HashSetEx
{
public static T[] ToSortedArrayEff<T>(this HashSet<T> hashSet)
{
var array = new T[hashSet.Count];
hashSet.CopyTo(array);
Array.Sort(array);
return array;
}
}
}
I tak naprawdę nie miałem zielonego pojęcia dlaczego ją stworzyłem i czemu nie wykorzystałem LINQ. Jednak skoro ją stworzyłem musiał być jakiś powód – przynajmniej dla mnie wtedy znany. Po kilku minutach przypomniałem sobie dlaczego ją napisałem – uważałem, że LINQu będzie mniej wydajne, za nic nie mogłem sobie tylko przypomnieć, dlaczego tak sądziłem.
Wykonałem więc dwa proste testy, wykorzystując .NET Framework 4.0 i Console Application oraz Silverlight 4 Application. Kod powyżej porównywałem z następującym poleceniem LINQ:
var linqHashSet = new HashSet<int>(data); linqHashSet.OrderBy(x => x).ToArray();
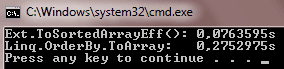
Wyniki trochę mnie z szokowały:


Ponad podwójna różnica w czasie wykonania sortowania. Test powtórzyłem na kilku komputerach i na wersji debug, release. Wyniki nie zeszły do mnie niż podwójnej różnicy czasu wykonania.
Zacząłem się zastanawiać dlaczego różnica jest taka kolosalna. Zrobiłem podobny test, tylko, że tym razem przy LINQ zamiast wykorzystywać HashSet<> (SL, .NET 4.0), wykorzystałem List<> (SL, .NET 4.0) – wyniki się nie różniły. Zamieniłem więc kod dla List<> by najpierw zrobił Sort() (SL, .NET 4.0), a potem wykonał metodę ToArray() (SL, .NET 4.0):
var list = new List<int>(data); list.Sort(); list.ToArray();
Dopiero wtedy wyniki zaczęły być lepsze o max 3 setne sekundy (różnica polega na tym, że List<>.ToArray bezpośrednio odwołuje się do metody Array.Copy, zaś HashSet<> nie ma takiej metody i trzeba wykonać operację HashSet<>.CopyTo która w pętli kopiuje elementy).
Problem więc nie leży w listach, ale w LINQ extension methods. Ba, implementacja List<>.ToArray() jest efektywniejsza niż implementacja extension method ToArray() (SL, .NET 4.0) – List<>.ToArray() – 0ms, LINQ ToArray() – 2,0526ms.
Czyli pierwszy problem to konwersja do tablicy. Po kilku chwilach przeszukiwania .NET reflectora znalazłem to czego szukałem: różnicą pomiędzy LINQ ToArray() a List<>.ToArray() jest pośrednia struktura Buffer, którą wykorzystuje LINQu by w ostateczności zwrócić to samo co List<>.ToArray().
Teraz, jeżeli wykonujemy czyste wywołanie LINQ ToArray to opóźnienie głównie wynika z faktu castowania naszej listy na inne typy jak ICollection<> na których wywoływana jest metoda CopyTo, co zajmuje więcej niż sama operacja List<>.ToArray.
Jednakże ze względu na to, że najpierw wykonywany w moim przypadku jest OrderBy, lista jak i HashSet nie są już typu ICollection<T> a są IOrderedEnumerable<T>. Przez co występuje problem z konstruktorem struktury Buffer. Mianowicie tworzy on domyślnie tablicę 4 elementową i jeżeli nasza lista posiada więcej elementów niż 4, wykonuje on operacje rozszerzenia tablicy: stworzenie nowej tablicy o rozmiarze 2 krotnie większym od poprzedniego, wykonanie operacji kopiowania danych z jednej tablicy do drugiej. Czyli dla 200 elementów, operacja kopiowania wykonywana jest 6 razy i nasza końcowa tablica posiada 256 elementów (to jest dość ważne). Następnie LINQ ToArray(), wywołuje na Buffer metodę ToArray, która sprawdza, czy liczba elementów w tablicy jest równa długości tablicy, jeżeli nie, to wykonywana jest operacja kopiowania tablicy po raz kolejny (7 w naszym przypadku) – w przypadku kiedy jednak nasz typ jest ICollection<> to problem kolejnego kopiowania tablicy nie występuje. Kod struktury Buffer przekopiowany z .NET Reflectora:
// copyright: Microsoft Corporation, copied from
// .NET Reflector for blog purpose only
[StructLayout(LayoutKind.Sequential)]
internal struct Buffer<TElement>
{
internal TElement[] items;
internal int count;
internal Buffer(IEnumerable<TElement> source)
{
TElement[] array = null;
int length = 0;
ICollection<TElement> is2 = source as ICollection<TElement>;
if(is2 != null)
{
length = is2.Count;
if(length > 0)
{
array = new TElement[length];
is2.CopyTo(array, 0);
}
}
else
{
foreach(TElement local in source)
{
if(array == null)
{
// domyslna wielkosc tablicy 4
array = new TElement[4];
}
else if(array.Length == length)
{
// zwiekszenie i kopiowanie tablicy
TElement[] destinationArray = new TElement[length * 2];
Array.Copy(array, 0, destinationArray, 0, length);
array = destinationArray;
}
array[length] = local;
length++;
}
}
this.items = array;
this.count = length;
}
internal TElement[] ToArray()
{
if(this.count == 0)
{
return new TElement[0];
}
// count inny niz dlugosc?
if(this.items.Length == this.count)
{
return this.items;
}
// kopiujemy
TElement[] destinationArray = new TElement[this.count];
Array.Copy(this.items, 0, destinationArray, 0, this.count);
return destinationArray;
}
}
Dla porównania, metoda List<>.ToArray():

Więc zyskujemy mniej więcej 6 krotnie na liście z 200 elementami.
Skoro wiemy, że ToArray jest lepsze (szybsze) kiedy albo ją sobie sami napiszemy albo skorzystamy z kolekcji, która implementuje sama ToArray nie wykorzystując LINQ, to co zrobić z metodą OrderBy (SL, .NET 4.0)?
LINQ OrderBy w bebechach w końcu wywołuje Quick Sort na elementach jednak zanim to nastąpi lista jest przeglądana minimum raz zbierając informacje o kluczach. Zaś List<>.Sort wywołuje bezpośrednio metodę Array.Sort (SL, .NET 4.0), która w efekcie też korzysta z implementacji Quick Sort, jednakże czas jej wykonania jest szybszy o 2ms.
Podsumowanie
Osobiście zdziwiła mnie aż taka różnica w czasie wykonania, w szczególności, iż test przeprowadzałem 200 razy w pętli na max 3000 elementowych List/HashSet. Może nie są to jakieś znaczące różnice, jednak kiedy zaczyna się pisać aplikację w SL, to warto się zastanowić nad tym czy aby na pewno mamy wszystko robić powolnie czy jeżeli mamy taką możliwość to należy nasz kod przyspieszyć. Jest to może mikro optymalizacja jednak jest.
By zachować kompatybilność testów pomiędzy SL a .NET Framework, nie używałem nowych list SortedSet i SortedList, gdyż byłoby to nie fair :) w SL takich list nie ma.
PS.: Wszystkie testy wykonywałem na HashSet<int>, List<int>. By przymusić List<int> by korzystała z extension methods z castowałem ją na IEnumerable<int>. Mój kod w aplikacji SL też działa na <int>, a wykorzystuje HashSet by pozbyć się duplikatów gdyż inaczej miałbym baaardzo nie wydajną metodę przechodzenia i analizowania czy wkładam unikatowy element do listy.
PS2.: Czasami fajnie jest mieć jakieś przyzwyczajenia i pewne przypuszczenia podczas pisania kodu – tak jak ja miałem przy pisaniu extension method, jednak czasami to może pójść dużo za daleko gdyż w trakcie przeglądania znalazłem także taki o to kod:
using System;
using System.Collections.Generic;
namespace SlPerfTest
{
public static class ListEx
{
public static T[] ToSortedArrayEff<T>(this IList<T> list)
{
var array = new T[list.Count];
list.CopyTo(array, 0);
Array.Sort(array);
return array;
}
}
}
Załamka? :)
")



{kind=link}