











Zaczynamy wchodzić w bardziej zaawansowane tematy z Elixir. Plan teraz jest dość prosty, dokończyć serię naukową i wejść w praktyczną – czyli napisać konkretną aplikację. Pomysł już jest :) Kwestia tylko omówienia kilku aspektów jeszcze i jazda :) Dziś więc na tapetę wchodzi maszyna wirtualna erlanga – BEAM (Bogdan/Björn’s Erlang Abstract Machine). Zrozumienie ogólne jak działa maszyna, umożliwi nam zrozumienie jak działają poszczególne elementy naszego systemu w Elixir.
Uwaga: słowo proces będzie używane dość często. Za każdym razem jak będę je używał to mam na myśli proces maszyny wirtualnej erlanga – stworzony i zarządzany przez nią, nie przez system operacyjny. Jeżeli będzie inaczej, to wspomnę o tym.
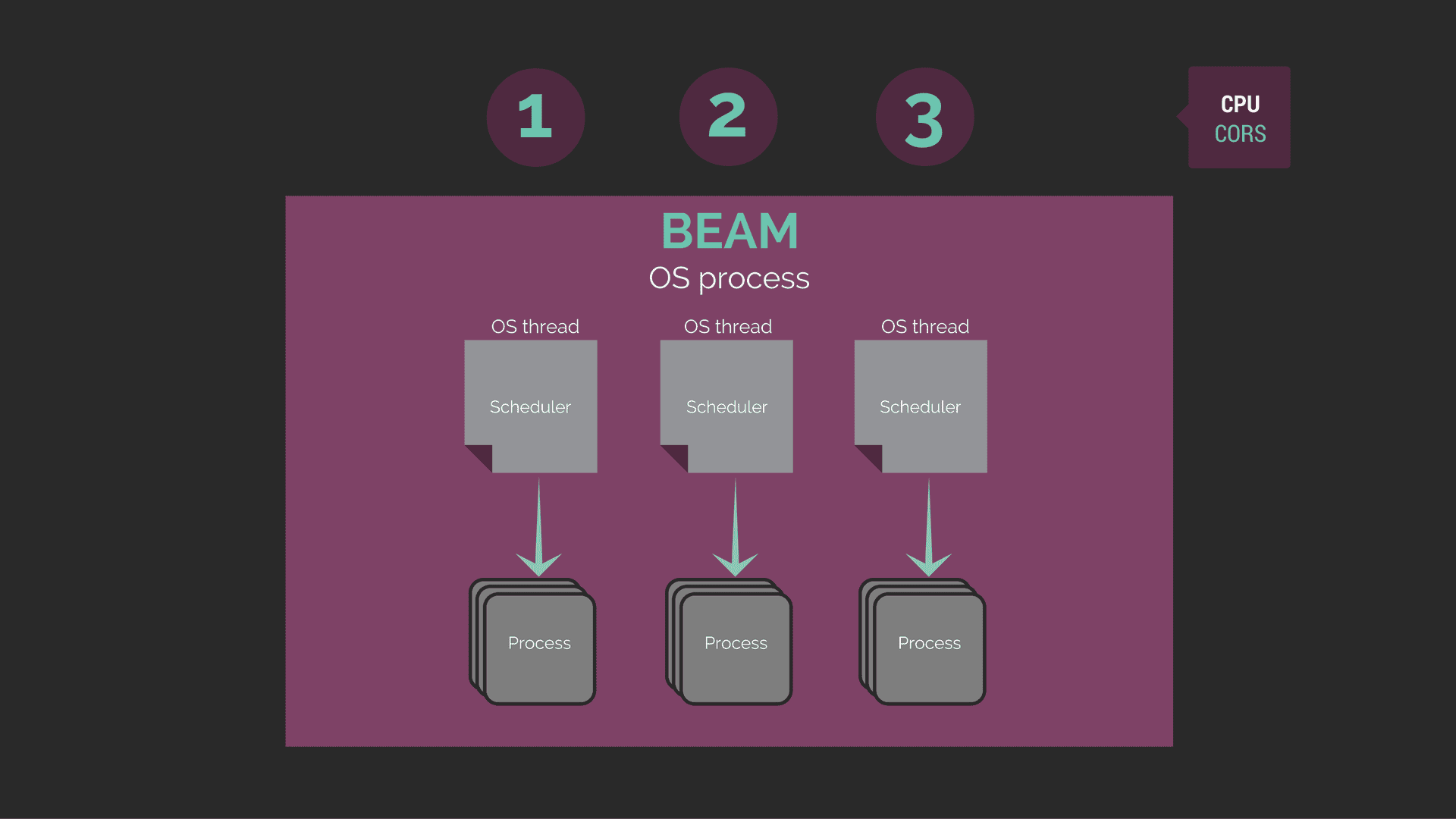
Zakładając wszystkie domyślne ustawienia, BEAM jest to pojedynczy proces systemu operacyjnego, który dla każdego rdzenia procesora tworzy scheduler odpowiedzialny zarządzaniem jednostkami pracy tak by jak najefektywniej wykorzystać dostępne procesory i jednostki pracy (procesy). Każdy taki scheduler działa jako osoby wątek w procesie systemu operacynego który został stworzony dla BEAM.
BEAM
Daje nam to kilka fajnych opcji (jak zawsze, na temat każdej można dyskutować):
- Fault tolerant (aż się zdziwiłem, że po PL tak to piszą ;))
- Skalowalność
- Rozpraszalność
Fault Tolerant
Każdy proces jest zamkniętą w sobie w całością – jest odizolowany. Procesy nie mają nic wspólnego między sobą – nie dzielą pamięci, obiektów, zmiennych. Jedyną rzeczą wspólną dla procesów jest to, że zarządza nimi scheduler. Jeżeli coś się stanie, to proces można usunąć. Można też wystartować nowy proces w miejscu tego który uległ awarii.
Izolacja procesów umożliwia działanie garbage collectora na bazie procesu a nie całości systemu. To znaczy, że może następować optymalizacja w procesie czyszczenia pamięci – każdy proces ma własnego garbage collectora. Ogólnie taki proces, dostaje około 2KB pamięci – mało, ale o to chodzi, wiele małych procesów. Jeżeli proces wymaga więcej niż 2KB, to w tym momencie do okna czasu wykonania (process execution window) dodawany jest garbage collector na danym procesie. A więc zamiast jednego wielkiego, słusznego procesu czyszczenia pamięci, mamy masę, setki, tysiące małych.
Skalowalność
Z powodu izolacji procesów, komunikacja pomiędzy nimi musi następować na zasadzie wiadomości asynchronicznych – taki mały pub/sub. Dzięki czemu nie następuje problem synchronizacji aktualnego stanu – lock, mutex, semafor itp. A skoro procesy są małe, to można ich tworzyć dużo. Więc jak trzeba nad czymś mocniej popracować, można łatwo zwiększyć obroty za pomocą zrównoleglenia pracy i wykorzystać w pełni wszystkie dostępne rdzenie w procesorze.
Czyli, za pomocą na przykład dołożenia RAM lub nowego procesora, ten sam kod, zacznie pracować znacznie wydajniej gdyż w pełni wykorzysta dodatkowe zasoby które zostały dostarczone. I nie będziemy musieli nic z naszej programistycznej perspektywy zmieniać.
Rozpraszalność
I teraz tutaj wchodzi wszystko to co mówiliśmy wcześniej, procesy są odizolowane od siebie, komunikacja jest asynchroniczna. To więc czemu musimy się komunikować tylko z wykorzystaniem jednej maszyny? :) Skoro możemy skalować rozwiązanie dodając zasoby do serwera, to też powinniśmy móc skalować rozwiązanie (rozszerzać je) horyzontalnie, czyli za pomocą kolejnych serwerów.
I tak też jest. Nasze procesy za pomocą komunikacji asynchronicznej są nie tylko wstanie komunikować się pomiędzy sobą ale także pomiędzy różnymi instancjami BEAM na różnych komputerach.
Scheduler
Scheduler to narzędzie, które zarządza procesami, udostępniając im okno wykonania (execution window). Każdy scheduler działa w osobnym wątku systemu operacyjnego. W beam jest tyle schedulerów ile jest rdzeni w procesorze (jest to wartość domyślna, można też to modyfikować ustawieniami).
Każdy proces, który jest zarządzany przez pojedynczy schedulera, działa zamiennie – każdy proces dostaje takie samo okno wykonania. Jak czas się kończy, to proces jest wywłaszczany i kolejny proces dostaje swoją szansę. Dzięki czemu nie następuje blokada systemu kiedy jeden z procesów musi wykonać długotrwałą, ciężką pracę, która może trwać i trwać. Gdyby taki scheduler miał czekać na zakończenie pracy tego procesu to zarówno scheduler mógłby się przywiesić jak i byśmy stracili responsywność całego systemu – pozostałe procesy by czekały na skończenie pracy pierwszego procesu.
Proces
Proces to najmniejsza jednostka pracy. Działa ona zawsze sekwencyjnie – do póki nie skończy pracy, nie może podjąć się nowej. Jedynie instancje procesów mogą działać współbieżnie. Czyli jeżeli chcemy wykonać zadania równolegle, to nie zrobimy tego z wykorzystaniem jednego procesu. Musimy mieć dwa procesy (oraz oczywiście dwa rdzenie w procesorze).
Jedynie komunikacja pomiędzy procesami jest asynchroniczna. Czyli jeżeli mamy jeden proces, który jest odpowiedzialny za przechwytywanie komunikacji z tysiąca innych procesów, to ten nasz proces będzie naszym bottleneck. Ze względu na to, że cała komunikacja będzie kolejkowana do póki proces nie skończy swojej pracy. To znaczy, że jeżeli coś trwa u nas jedną sekundę a mamy 10 wiadomości już wysłanych, to ostatnia zostanie dopiero przetworzona po upływnie 10 sekundy.
Podsumowanie
Oki, trochę suchej teorii bez wchodzenie w zbytnio w szczegóły. Ale to da nam podstawy do następnego artykułu w którym pewne rzeczy z tego zostaną jeszcze bardziej rozwinięte.
side note: Pamiętacie jak cały czas chodziłem za tym jak to jest z tymi modułami? Kto i co jest odpowiedzialny za ich inicjalizację itp. ;) No to jest to tak, że kod źródłowy jest kompilowany do plików beam które są wykorzystywane przez maszynę wirtualną. Jeżeli coś nie zostało załadowane, to maszyna wirtualna szuka skompilowanej wersji modułu (każdy moduł ma osobny beam) i próbuje ją załadować i następnie wykonać funkcję. A więc częściowo sobie odpowiedziałem przy okazji jak to tak naprawdę jest szykując ten krótki suchy opis ;)
")



{kind=link}
[…] Elixir #11 – BEAM […]
[…] z wykorzystaniem Azure Functions. O Actor Model nie pisałem ale wspominałem przy elixir przy opisie BREAM (tak mniej więcej może wyglądać implementacja Actor […]
Comments are closed.