










Mads Kristensen odwalił kawał dobrej roboty tworząc Web Essentials. Jest to pierwsze narzędzie wspierające analizę JS, kompilowanie LESS, minimalizację CSS i JS i wiele innych rzeczy, które naprawdę mnie nie wkurza. I w większości przypadków działa.
No właśnie, w większości. Dwa dni temu zacząłem przepisywać swój nowy projekt z CSS na LESS – by się go nauczyć, pobawić i w ogóle. Jednak z miejsca natrafiłem na problem, którego za nic nie mogłem obejść – przynajmniej do póki się nie zorientowałem, dlaczego tak się dzieje.
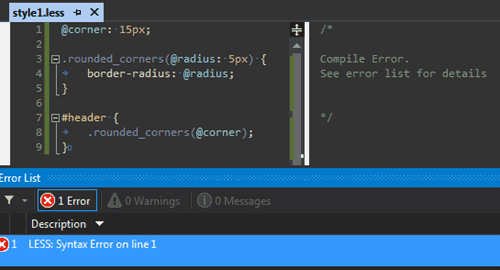
Otworzyłem nowy plik LESS, skopiowałem dosłownie to samo, co można znaleźć w przykładzie na stronie Web Essentials i dostałem piękny błąd:

Nic niemówiący, a co gorsza w innych kompilatorach to ślicznie działa. Więc tym bardziej zastanawiający. Próbowałem kilku rozwiązań jak dodanie komentarza do pierwszej linijki, pozbycie się @corner i wstawienia tam gdzie chciałem 15px i nic nie pomogło. Nawet dodawałem pustą metodę bez parametru na początku pliku i wciąż był taki sam błąd.
Zacząłem, więc odpytywać Mads’a jak on to kompiluje, czy to wina dotLess czy może czegoś innego. Dowiedziałem, się, że nie wykorzystuje on .NETowego portu kompilatora LESS a oryginalny kompilator less z wykorzystaniem małego skryptu lessc.wsf.
Szybki test kompilacji, pokazał mi, że są jakieś dziwne znaki na początku pliku:

Co doprowadziło chyba do najszybszego rozwiązania problemu z plikami LESS w WE. Mianowicie z File Menu wybieramy opcję Advanced Save Options i wybieramy encodowanie na UTF-8 without signature (czyli bez BOM) – tak jak na obrazku:

Od tej pory wszystko będzie nam ładnie działało dla pliku.
Inną opcją rozwiązania o której dowiedziałem się dzisiaj jest dodanie pustej klasy CSS na początku pliku – dzięki Arkadiusz!:
.dummy {}
Oczywiście musimy to dodać do każdego pliku LESS.
Zaś wszystkie te rozwiązania są tak naprawdę obejściem problemu. Jakiego? Mianowicie lessc.wsf wykorzystuje Scripting.FileSystemObject do otwarcia i odczytania pliku za pomocą metody OpenTextFile. Metoda ta nie czyta byte po byte ale znak po znaku dany plik i dokonuje o dziwo jakieś konwersji, mianowicie znaki zapisane w Windows 1250 (polskie ustawienia regionalne) traktuje jako znaki UTF-8, przez co, nasz BOM który był zakodowany jako EF BB BF, zostaje zamieniony na znaki o kodach 10F BB 17C. Czyli jakakolwiek blokada przed BOM tutaj nie zadziała – nie ma szans. Jedyną opcją rozwiązania tego jest albo dodanie 10F BB 17C jako znaków do wykasowania podczas odczytywania pliku albo po prostu kasowania wszystkich dziwnych znaków do pierwszego rozpoznawalnego takiego jak / @ . # czy też litera. Jeżeli plik lessc.wsf wykorzystywany przez WE się zmodyfikuje by w metodzie readText usuwał także znaki 10F BB 17C, to nie trzeba nic więcej robić z poziomu VS (czy to dummy class czy zmiana enkodowania znaków).
Wiem, że Mads pracuje już nad poprawieniem tego issue i sądzę, że niebawem albo poprzez normalny kanał albo poprzez kanał nightly builds nowy build z poprawką będzie dostępny.
Do tego czasu, albo chcecie się grzebać w WSH, albo stosujcie proste dwa obejścia:)
Jak chcecie się grzebać w WSH, to tutaj macie kod, który na pewno wam zadziała.
Miłego LESSowania :)
")



{kind=link}