











W zeszłym tygodniu powiedzieliśmy sobie o funkcjach wyższego rzędu. W tym tygodniu skoncentruje się na dwóch funkcjach, które do funkcji wyższego rzędu należą – Map i Filter. Są to proste funkcje i raczej nie sprawią problemu ze zrozumieniem. Jednak skoro piszemy o wszystkich to o nich też trzeba.
Z cyklu funkcje wyższego rzędu, do tej pory ukazały się artykuły:
- Funkcje wyższego rzędu
- Map i Filter
- Fold/Reduce
- Currying
Map
Map jest funkcją która dla każdego elementu danych wejściowych wykonuje funkcję pojedynczo na wszystkich elementach danych wejściowych, zwracając dane w tej samej kolejności co dane wejściowe. Funkcja, która jest wykonywana na elemencie zazwyczaj zmienia/transformuje dane wejściowe.
Funkcja która jest wykonywana na elementach w celu ich transformacji jest całkowicie dowolna, to może być mnożenie, podnoszenie do kwadratu, czy też zamiana typów danych. Można to dość krótko przedstawić za pomocą obrazka:
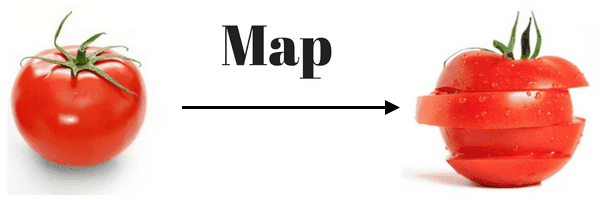
Zrozumiałe? :)
W C# mamy dwie funkcje które nam umożliwiają mapowanie. Pierwsza z nich jest znana od wprowadzenia LINQ – Select. Druga od .NET 4.0 Zip. Dla przykładu mając dane wejściowe w postaci listy osób:
public class Person
{
public string FirstName { get; set; }
public string LastName { get; set; }
public string Email { get; set; }
public int Age { get; set; }
}
var people = new List<Person> { /****/ };
Możemy z mapować wszystkich ludzi do listy adresów e-mail:
people.Select(x => x.Email);
Albo, możemy podnieść do kwadratu każdą liczbę z przedziału od 1 do 100:
Enumerable.Range(0, 100).Select(x => x * x);
Drugą funkcją C# jest funkcja Zip, która wykonuje funkcję mapującą na wszystkich elementach dwóch list. Listy na której metoda została wykonana, i listy przekazanej w parametrze. Wynikiem jest pojedyncza lista zwierająca tyle elementów ile elementów zawiera najkrótsza z list. Dla przykładu, jeżeli metodę zip wykonamy na liście 6 elementowej, ale do metody przekażemy 3 elementową listę to wynikiem będzie lista 3 elementowa. Ogólnie Zip bierze po tym samym elemencie (po index) z dwóch list i wykonuje na nich funkcję. Jak w jednej z list nie ma takiego indexu, to kończy działanie. Funkcja mapująca zaś, przejmuje dwa parametry, pierwszy to element z listy na której metoda jest wołana, drugi to element z listy która została przekazana do Zip.
Enumerable
.Range(0, 5)
.Zip(Enumerable.Range(0,3), (f,s) => f*s)
Wynikiem będzie lista trzy elementowa zawierająca wartości 0, 1, 4.
W F# mamy podobnie, z tą różnicą iż metody zwą się map i map2. Przy czym map2 wyrzuca wyjątek jeżeli listy są o różnych długościach.
let list = [1;2;3] let map = list |> List.map(fun x -> x*x) printf "%A" map let list1 = ["ala";"kota";"a";"ma"] let list2 = [" ma";", ";" kot";" ale"] let map = List.map2 (fun f s -> f + s) list1 list2 printf "%A" map
Metody map i map2 są dostępne dla różnych kolekcji (Seq, List, Map itp.).
To tyle jeżeli chodzi o funkcję mapującą.
Filter
Funkcja wyższego rzędu filter to taka funkcja, która dla każdego elementu danych wejściowych wykonuje funkcję która zwraca wartość true lub false. Jeżeli wartość zwrócona przez funkcję to false, dane nie pojawią się w wyniku końcowym. Jeżeli true, do wyniku końcowego dane są dodawane.
Można to zobrazować za pomocą obrazka:

W C# typową funkcją filtrującą jest Where. Dla przykładu, poniższa funkcja zwróci wszystkich ludzi, którzy są starsi niż 10 lat. Jeżeli takich ludzi nie ma, zostanie zwrócona pusta lista.
people.Where(x => x.Age > 10)
W F# istnieje zaś funkcja która się zwie filter. Dla przykładu, w taki o to sposób możemy zwrócić listę wszystkich parzystych liczb z przedziału 1..10:
[1..10] |> List.filter (fun x -> x%2 = 0)
Podsumowanie
Jak widać, funkcje Map i Filter nie są ciężkie i trudne do zrozumienia. Chodzi jedynie o fakt przekazywania funkcji jako parametru wejściowego. Pewnie z nich korzystaliście nie zastanawiając się nawet, że zwą się one funkcjami wyższego rzędu – i dobrze. Jednak dobrze wiedzieć i znać tę nazwę, gdyż jak się ona pojawi na interview… to nawet wiedząc i znając wszystkie metody możemy nie skumać o co biega.
Cieszę się też, że udało mi się zamknąć te funkcje za jednym razem. Za tydzień postaram się opowiedzieć o najtrudniejszej do zrozumienia funkcji wyższego rzędu, postaram się to też tak opisać, by każdy to zrozumiał. A więc do przeczytania niebawem :)
")



{kind=link}